- Prof. Dancy's Site - Course Site -
AI & Cognitive Science Neural Net Assignment
Final Submission Due (Area/Cohort 1): 04-March-2021 Final Submission Due (Area/Cohort 2): 23-Apr-2021
If you haven't done so already, Create a new repo on Gitlab called CSCI357-SP21
Let's create a new AI Agent architecture and use it in Minecraft!
Groups of 2 (Pairs)
Directions
Create a folder, NN, in the CSCI357-SP21 git repo
For this assignment, we want to create an AI agent architecture that can allow us to accomplish a task in Minecraft - stay alive for as long as possible (and get a good score along the way)!
It's going to be your job to design this AI agent architecture and implement that design.
You'll need to analyze both the environment and the what you can do within this environment along the way to developing your design & implementation. At minimum, your agent will need to have a way to perceive it's environment, use a central decision engine to make a decision on what action to carry out, and a way to enact action on that environment.
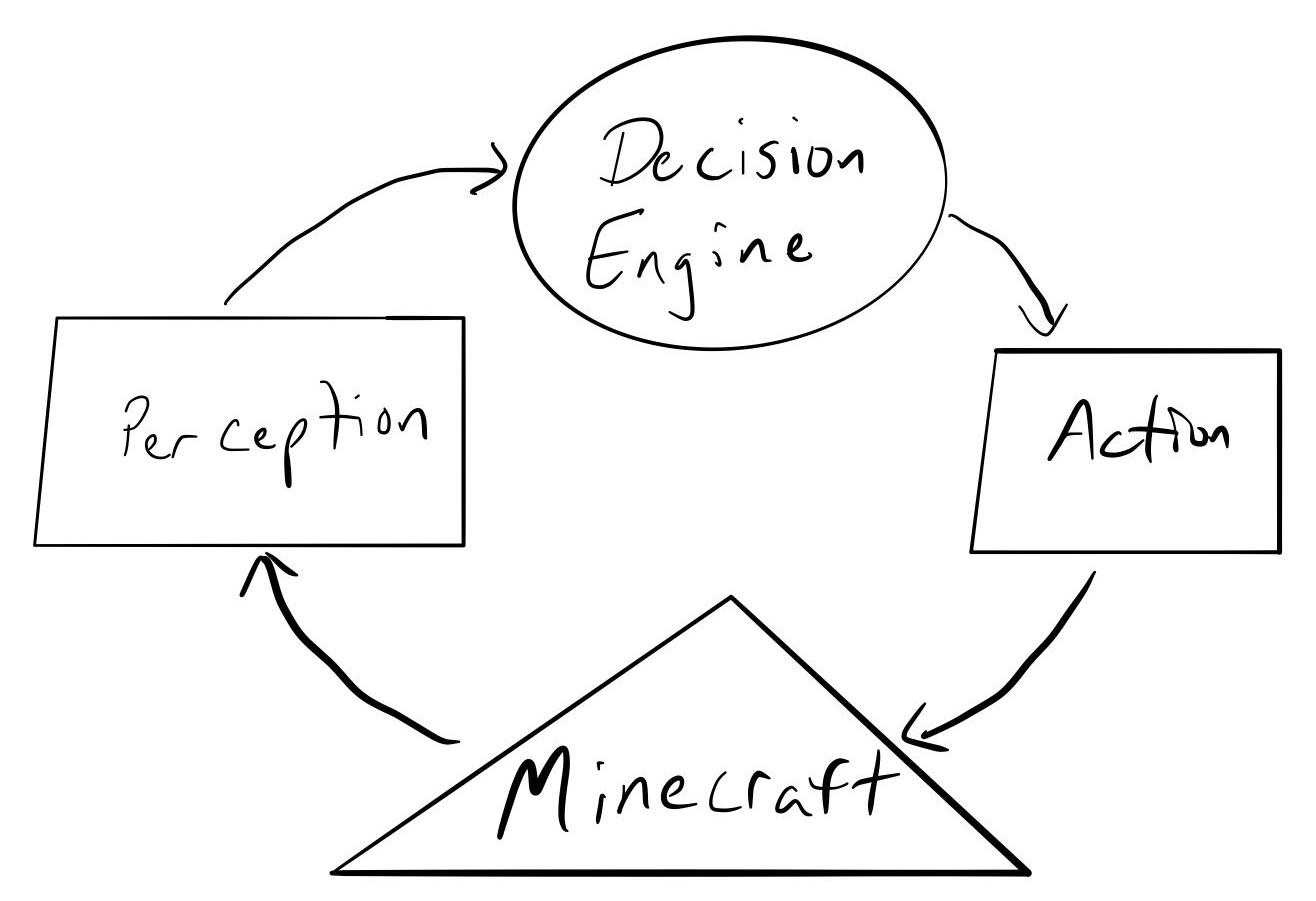
Figure 1: Prof. Dancy's crappy quick drawing
Figure 1 above gives a high-level picture of what this might look like. Notice that we've essentially created a high-level AI/cognitive architecture! It's going to be up to you to define the details, and if you believe it's warranted develop additional aspects/modules of the architecture.
Your central decision engine must be powered by a Neural Network. Particularly, you'll need to both write your own Neural Network class from the ground up and develop a class that allows a Keras-based (dense) Neural Network. That is, your decision-engine should be able to swap which Neural Network it is going to use.
What problem are we going to solve with our new shiny AI agent architecture?
Your agent will need to run around in a room and collect as many apples as possible to gain points.
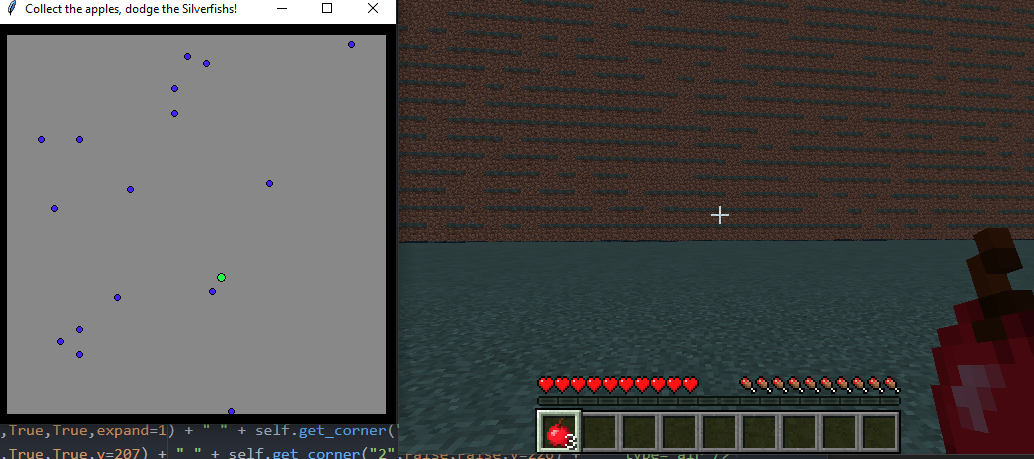 Figure 2: Happy agent eatin apples and such
Figure 2: Happy agent eatin apples and such
However, be aware that as your agent picks up apples (and gain points) it may trigger a mob of dangerous silverfish to spawn and try to kill it!

Figure 3: Image from https://minecraft.gamepedia.com/Silverfish
You agent will have to move throughout the environment and pickup the apples to gain points (and potentially regain life) all the while potentially dodging those dangerous mobs!
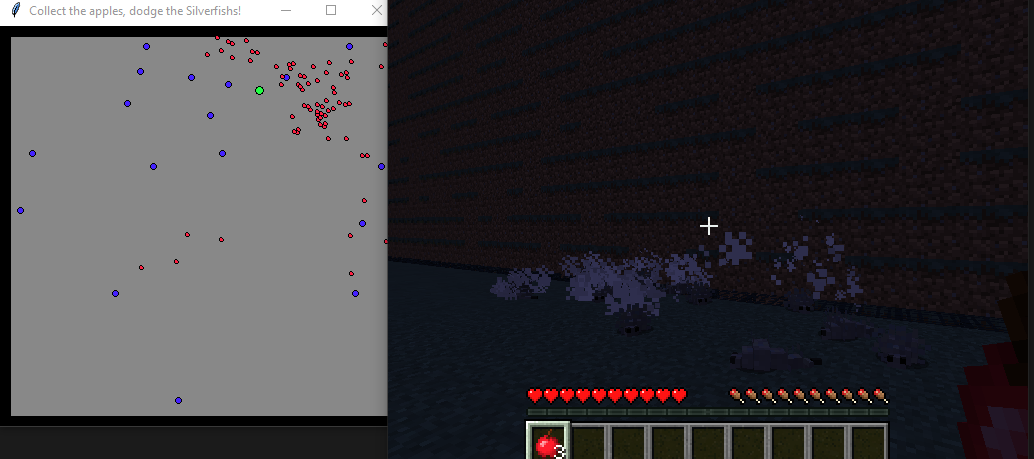
Figure 4
What should be in my solution?
There are several artifacts that you'll need to create along the way. I've separated them into stages to make it a bit easier to judge initial ordering. I'd assume you'd want to iterate through for some of these artifacts (e.g., the design) as you continue in the process. At the end I'll want the final version of all of these artifacts :-). I list the artifacts I expect to see at the end of this section
Stage 1 - Initial AI Design, Suggested target date to finish: 15-Apr
-
General AI Design
- I want you to use the General AI Design sheet to make come up with initial specifications for the Environment that the agent will be operating within, the Goals the agent will need to have within this environment, and the adaptation the agent will need to carry out to accomplish these Goals in the given Environment.
- Take this aspect seriously! The more you understand these three things, the easier the agent will be to design (in later stages) & implement!
-
AI architecture design
- You'll need to understand what data you can perceive and how you might complete actions in the environment
- You should construct a high level design (e.g., like Figure 1 or Figure 5 below)
- You'll need to start to brainstorm what inputs your NN will take in and what outputs it will give, Of course this will be finalized at some point, but you want to have a draft before moving on to the next stage
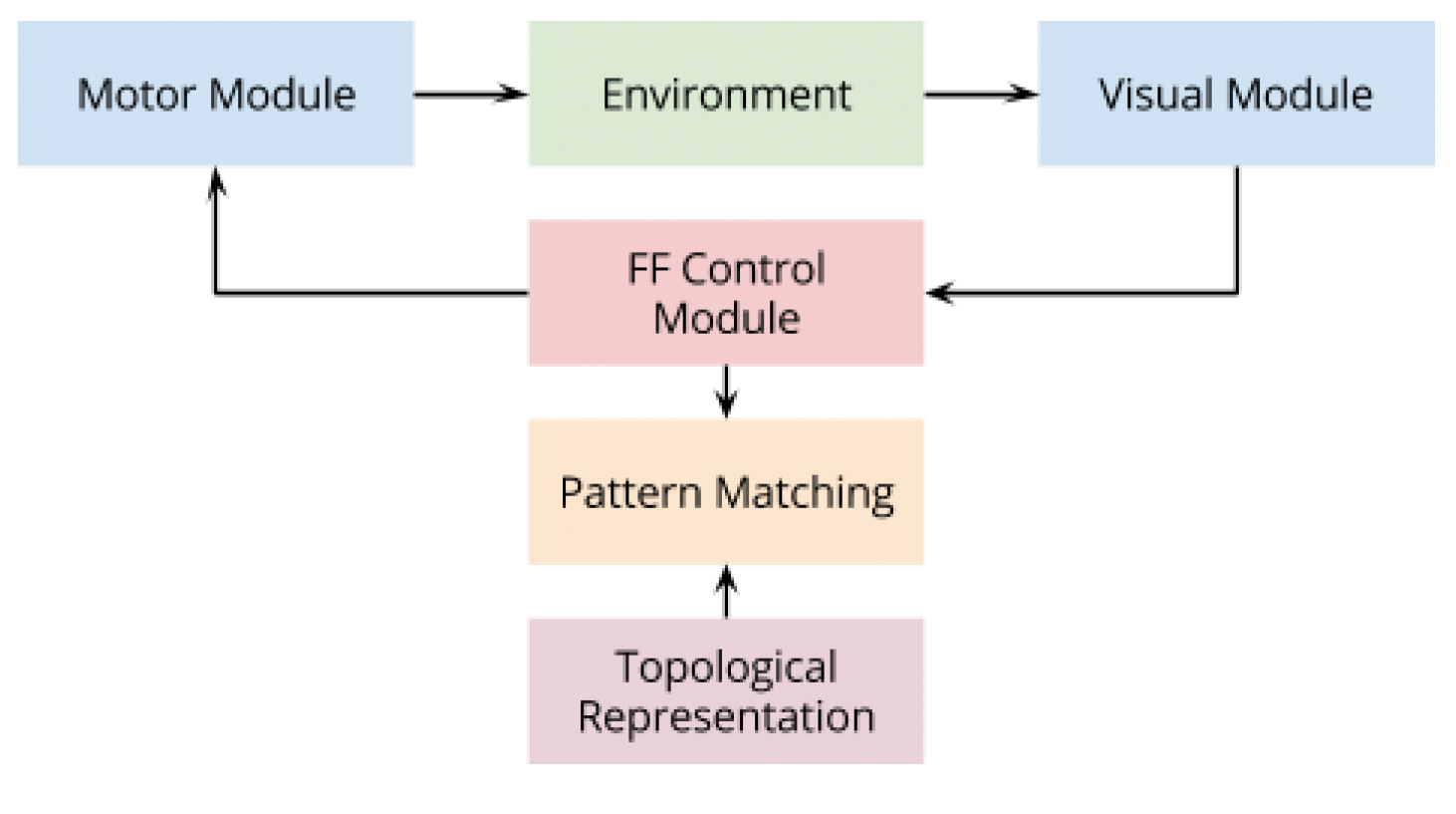
Figure 5: from final report from a previous "Intro to AI & CogSci" course, by Jasper Ding, Keyi Zhang, Tung Phan, and Son Pham
Stage 2 - Neural net practice & Initial code design, Suggested target date to finish: 18-Apr
- Neural Net Practice
- Fill out the Neural Network practice sheet (and save it for submission)
- General Code Design
- High-level classes & objects to be created/used
Stage 3 - Construct the Decision Engine of your architecture, Suggested target date to finish: 20-Apr
- Use Keras to construct your NN decision engine
- Come back to those early designs as a guide on what you're going to do
- You should lay out the parameters for your NN (number of layers, number of neurons in each layer, any optimizations, etc.)
- You should be able to swap out your NN for any other NN object (assuming it can take the given input and output)
- This means you should be able to have several versions of a NN as the engine (Assume I want to be able to pick it up and swap out your NN for my own with some simple importing and a new instance.)
- You should think about how you might want your agent to learn and how you're going to save the parameters so that your agent can learn & come back to that learned stage when it's ready for primetime
Stage 4 - User Keras to construct another NN-based Decision Engine, Suggested target date to finish: 21-Apr
- Modify your original Keras NN to try to add something to it (or if you're feeling brave, use another system like tensorflow)
- Test speed and performance of the original Keras inference engine vs this new engine
- What are the speed differences and why do you see them
- Are there are performance differences?
- If so, why?
Stage 6, Suggested target date to finish: 23-Apr
- You should have been documented along the way, but go back and document now any places that you may have missed
- Include the design docs, performance metrics (of your design w/ both inferences) and any insights you may have in a central README doc
Expected Artifacts
All non-code artifacts should be placed in a folder called docs in your NN folder.
- General AI Design sheet for your AI agent
- Design documentation for your AI agent architecture
- Design of your NN (the structure of the Neural Net - number of inputs, hidden layers, outputs, etc; Any optimizations that you plan to use w/ your NN)
- NN Practice sheet filled out
- Your code (The Keras-based NN Class + The agent architecture & solution for the Minecraft environment)
Note that I provide a shell for your NN class including the constructor in the appendix You do not have to use this code and are free to modify it as you want. However, in case you wanted to start somewhere once you get to the NN class stage, this is somewhere you can start!
Grading
| Grade item | Points |
|---|---|
| General AI design document present | 1 pts |
| AI agent architecture design present | 1 pts |
| Neural Net practice sheet present and correct | 2 pts |
| Neural Net can use different numbers of inputs and outputs (not hardcoded) | 1 pts |
| Neural Net can use different numbers of hidden nodes and layers | 1 pt |
| Keras Neural Net class complete and working as swappable decision engine | 4 pt |
| Good README with designs, information about the code, and performance metrics | 4 pt |
Appendix
In the sections that follow, you'll find installations instructions for malmo, the simulation code (I'd suggest calling it MalmoSim.py), and some Neural Net starter code
Instructions
Provided Files
The Malmo/Minecraft softwareThis is the software that you'll need to run a Minecraft server on your machine. I've provided a zip on Moodle for these files. You'll want to place each of the folders in the zip into the base directory of the simulation file that you'll be running.
Java 8
- You need Java 8 for this project. There's a chance that you don't have it if you're on a newer computer.
- You can check your java version by going to the shell/cmd and typing
java -versionif you see java 8 or java 1.8, you should be fine. - If you don't have Java 8 you might want to stick to mostly using the lab computers.
- Otherwise, Project Malmo has a link to an existing open Java 8 that can be downloaded - https://adoptopenjdk.net/
Getting Started with Malmo
Create a virtual Environment for the Python dependencies that you'll install for the project:
1. On any platform (Mac/Linux/Windows)
Create a virtual environment called malmoEnv
username$ python3 -m venv malmoEnv
2a. On a Mac/Linux machine, in the terminal
Activate environment called testEnv
username$ source malmoEnv/bin/activate
(Do not do this until you want to not use your virtual environment anymore)
To deactivate any virtual environment you are in
$ deactivate
2b. On a Windows machine, in cmd
Activate environment called malmoEnv
malmoEnv\Scripts\activate.bat
(Do not do this until you want to not use your venv)
To deactivate any virtual environment you are in
deactivate
You should see the name of your env next to your command line in the terminal/shell now, this is how you know that your virtual environment is activated
- For example it may look like this -
(malmoEnv) Labcomputer:project user1234$
Install the dependencies needed with pip
- Ensure you have your virtual environment loaded (see the example above)
- Ensure you have your virtual environment loaded (see the example above)
- Ensure you have your virtual environment loaded (see the example above)
- ... (if you type
which pythonin terminal orwhere pythonin cmd, you should see the path to your virutal environment listed first)
(malmoENV) username$ python -m pip install gym lxml numpy pillow
Congrats, you should all you need installed! Now let's move on to getting the files you need
Running the Malmo/Minecraft server
- In a second terminal window (separate from the one where you'll run your python commands):
- Navigate to the directory where your
Minecraft&Schemasfolders are located (the folders contained in the zip) - On Windows run the batch file
Minecraft\launchClient.bat -port 9000 -env - on Mac/Linux (your own computer) run the shell script
username$ sh Minecraft/launchClient.sh -port 9000 -env - On Linux (The Lab computers) load, java 8, then run the shell script
username$ module load java/1.8 username$ sh Minecraft/launchClient.sh -port 9000 -env
- Navigate to the directory where your
If you are on a lab computer, you will need to run module load java/1.8 before starting the Minecraft server each time in the same terminal
Running your agent
- Ensure that your server is up and running!
- In a separate terminal/cmd prompt activate your virtual environment
- Run the python command to start your main python file:
username$ python MalmoSim.py
- This should cause you to see the agent on the screen in a new environment on the Minecraft game screen! As you complete more of the agent, more of it will work correctly.
Hint:
- If you're debugging your code and want to stop your agent before the mission end (or you seem to be stuck in a loop)
- Navigate to the shell/cmd/IDLE that you used to run your agent, hit
ctrl+c - This will allow you to start the agent back up w/out having to restart the server
- If you exit on the server side 1st (e.g., Quit to the main screen), you will have to hit
ctrl+cto restart/rebuild the Minecraft server!!!
- Navigate to the shell/cmd/IDLE that you used to run your agent, hit
Project Malmo starter code (MalmoSim.py)
# ------------------------------------------------------------------------------------------------
# Copyright (c) 2016 Microsoft Corporation
#
# Permission is hereby granted, free of charge, to any person obtaining a copy of this software and
# associated documentation files (the "Software"), to deal in the Software without restriction,
# including without limitation the rights to use, copy, modify, merge, publish, distribute,
# sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all copies or
# substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT
# NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
# NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
# DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# ------------------------------------------------------------------------------------------------
'''Project Malmo Mob simulation adapted from demo in Malmo Python examples
(mob_fun). This version uses a bit more OOD and uses an agent object to make decisions
'''
import malmoenv
import os
import random
import argparse
import sys
import time
import json
import random
import errno
import math
import tkinter as tk
from collections import namedtuple
from NeuralMMAgent import NeuralMMAgent
EntityInfo = namedtuple('EntityInfo', 'x, y, z, name, colour, variation, quantity, yaw, pitch, id, motionX, motionY, motionZ, life')
EntityInfo.__new__.__defaults__ = (0, 0, 0, "", "", "", 1, 0, 0, 0, 0, 0, 0, 0)
class MalmoSim:
'''Class to run mob simulation w/ agents
'''
# Task parameters:
NUM_GOALS = 20
GOAL_TYPE = "apple"
GOAL_REWARD = 100
ARENA_WIDTH = 60
ARENA_BREADTH = 60
MOB_TYPE = "Silverfish" # Change for fun, but note that spawning conditions have to be correct - eg spiders will require darker conditions.
# Display parameters:
CANVAS_BORDER = 20
CANVAS_WIDTH = 400
CANVAS_HEIGHT = CANVAS_BORDER + ((CANVAS_WIDTH - CANVAS_BORDER) * ARENA_BREADTH / ARENA_WIDTH)
CANVAS_SCALEX = (CANVAS_WIDTH-CANVAS_BORDER)/ARENA_WIDTH
CANVAS_SCALEY = (CANVAS_HEIGHT-CANVAS_BORDER)/ARENA_BREADTH
CANVAS_ORGX = -ARENA_WIDTH/CANVAS_SCALEX
CANVAS_ORGY = -ARENA_BREADTH/CANVAS_SCALEY
def __init__(self, step_size=1, search_resolution=20, goal_weight=100, \
edge_weight=-100, mob_weight=-10, turn_weight=0):
# Agent parameters:
self.agent_step_size = step_size
self.agent_search_resolution = search_resolution # Smaller values make computation faster, which seems to offset any benefit from the higher resolution.
self.agent_goal_weight = goal_weight
self.agent_edge_weight = edge_weight
self.agent_mob_weight = mob_weight
self.agent_turn_weight = turn_weight # Negative values to penalise turning, positive to encourage.
#output is the binary representation of our output index ([o,search_resolution))
self.agent_decision_net = NeuralMMAgent(search_resolution, \
search_resolution, 2, math.ceil(math.log(search_resolution,2)), \
random_seed=10, max_epoch=50000, learning_rate=0.25, momentum=0.95)
self.training_obs = []
self.training_out = []
self.root = tk.Tk()
self.root.wm_title("Collect the " + MalmoSim.GOAL_TYPE + "s, dodge the " + MalmoSim.MOB_TYPE + "s!")
self.canvas = tk.Canvas(self.root, width=MalmoSim.CANVAS_WIDTH, height=MalmoSim.CANVAS_HEIGHT, borderwidth=0, highlightthickness=0, bg="black")
self.canvas.pack()
self.root.update()
#----Begin Mission XML Section----#
def get_item_xml(self):
''' Build an XML string that contains some randomly positioned goal items'''
xml=""
for item in range(MalmoSim.NUM_GOALS):
x = str(random.randint(-MalmoSim.ARENA_WIDTH/2,MalmoSim.ARENA_WIDTH/2))
z = str(random.randint(-MalmoSim.ARENA_BREADTH/2,MalmoSim.ARENA_BREADTH/2))
xml += '''<DrawItem x="''' + x + '''" y="210" z="''' + z + '''" type="''' + MalmoSim.GOAL_TYPE + '''"/>'''
return xml
def get_corner(self, index,top,left,expand=0,y=206):
''' Return part of the XML string that defines the requested corner'''
x = str(-int(expand+MalmoSim.ARENA_WIDTH/2)) if left else str(int(expand+MalmoSim.ARENA_WIDTH/2))
z = str(-int(expand+MalmoSim.ARENA_BREADTH/2)) if top else str(int(expand+MalmoSim.ARENA_BREADTH/2))
return 'x'+index+'="'+x+'" y'+index+'="' +str(y)+'" z'+index+'="'+z+'"'
def get_mission_xml(self, summary):
''' Build an XML mission string.'''
spawn_end_tag = ' type="mob_spawner" variant="' + MalmoSim.MOB_TYPE + '"/>'
return '''<?xml version="1.0" encoding="UTF-8" ?>
<Mission xmlns="http://ProjectMalmo.microsoft.com" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<About>
<Summary>''' + summary + '''</Summary>
</About>
<ModSettings>
<MsPerTick>20</MsPerTick>
</ModSettings>
<ServerSection>
<ServerInitialConditions>
<Time>
<StartTime>13000</StartTime>
<AllowPassageOfTime>false</AllowPassageOfTime>
</Time>
<AllowSpawning>true</AllowSpawning>
<AllowedMobs>''' + MalmoSim.MOB_TYPE + '''</AllowedMobs>
</ServerInitialConditions>
<ServerHandlers>
<FlatWorldGenerator generatorString="3;7,220*1,5*3,2;3;,biome_1" />
<DrawingDecorator>
<DrawCuboid ''' + self.get_corner("1",True,True,expand=1) + " " + self.get_corner("2",False,False,y=226,expand=1) + ''' type="grass"/>
<DrawCuboid ''' + self.get_corner("1",True,True,y=207) + " " + self.get_corner("2",False,False,y=226) + ''' type="air"/>
<DrawLine ''' + self.get_corner("1",True,True) + " " + self.get_corner("2",True,False) + spawn_end_tag + '''
<DrawLine ''' + self.get_corner("1",True,True) + " " + self.get_corner("2",False,True) + spawn_end_tag + '''
<DrawLine ''' + self.get_corner("1",False,False) + " " + self.get_corner("2",True,False) + spawn_end_tag + '''
<DrawLine ''' + self.get_corner("1",False,False) + " " + self.get_corner("2",False,True) + spawn_end_tag + '''
<DrawCuboid x1="-1" y1="206" z1="-1" x2="1" y2="206" z2="1" ''' + spawn_end_tag + '''
''' + self.get_item_xml() + '''
</DrawingDecorator>
<ServerQuitWhenAnyAgentFinishes />
</ServerHandlers>
</ServerSection>
<AgentSection mode="Survival">
<Name>The Hunted</Name>
<AgentStart>
<Placement x="0.5" y="207.0" z="0.5"/>
<Inventory>
</Inventory>
</AgentStart>
<AgentHandlers>
<VideoProducer want_depth="false">
<Width>640</Width>
<Height>480</Height>
</VideoProducer>
<ChatCommands/>
<ContinuousMovementCommands turnSpeedDegs="360"/>
<AbsoluteMovementCommands/>
<ObservationFromNearbyEntities>
<Range name="entities" xrange="'''+str(MalmoSim.ARENA_WIDTH)+'''" yrange="2" zrange="'''+str(MalmoSim.ARENA_BREADTH)+'''" />
</ObservationFromNearbyEntities>
<ObservationFromFullStats/>
<RewardForCollectingItem>
<Item type="'''+MalmoSim.GOAL_TYPE+'''" reward="'''+str(MalmoSim.GOAL_REWARD)+'''"/>
</RewardForCollectingItem>
</AgentHandlers>
</AgentSection>
</Mission>'''
#----End Mission XML Section----#
def find_us(self, entities):
for ent in entities:
if ent.name == MalmoSim.MOB_TYPE:
continue
elif ent.name == MalmoSim.GOAL_TYPE:
continue
else:
return ent
def get_scores(self, entities, current_yaw, current_health):
us = self.find_us(entities)
scores=[]
# Normalise current yaw:
while current_yaw < 0:
current_yaw += 360
while current_yaw > 360:
current_yaw -= 360
# Look for best option
for i in range(self.agent_search_resolution):
# Calculate cost of turning:
ang = 2 * math.pi * (i / float(self.agent_search_resolution))
yaw = i * 360.0 / float(self.agent_search_resolution)
yawdist = min(abs(yaw-current_yaw), 360-abs(yaw-current_yaw))
turncost = self.agent_turn_weight * yawdist
score = turncost
# Calculate entity proximity cost for new (x,z):
x = us.x + self.agent_step_size - math.sin(ang)
z = us.z + self.agent_step_size * math.cos(ang)
for ent in entities:
dist = (ent.x - x)*(ent.x - x) + (ent.z - z)*(ent.z - z)
if (dist == 0):
continue
weight = 0.0
if ent.name == MalmoSim.MOB_TYPE:
weight = self.agent_mob_weight
dist -= 1 # assume mobs are moving towards us
if dist <= 0:
dist = 0.1
elif ent.name == MalmoSim.GOAL_TYPE:
weight = self.agent_goal_weight * current_health / 20.0
score += weight / float(dist)
# Calculate cost of proximity to edges:
distRight = (2+MalmoSim.ARENA_WIDTH/2) - x
distLeft = (-2-MalmoSim.ARENA_WIDTH/2) - x
distTop = (2+MalmoSim.ARENA_BREADTH/2) - z
distBottom = (-2-MalmoSim.ARENA_BREADTH/2) - z
score += self.agent_edge_weight / float(distRight * distRight * distRight * distRight)
score += self.agent_edge_weight / float(distLeft * distLeft * distLeft * distLeft)
score += self.agent_edge_weight / float(distTop * distTop * distTop * distTop)
score += self.agent_edge_weight / float(distBottom * distBottom * distBottom * distBottom)
scores.append(score)
return (scores)
def get_best_angle(self, entities, current_yaw, current_health):
'''Scan through 360 degrees, looking for the best direction in which to take the next step.'''
scores = self.get_scores(entities, current_yaw, current_health)
# Find best score:
i = scores.index(max(scores))
# Return as an angle in degrees:
return (i, scores, i * 360.0 / float(self.agent_search_resolution))
def canvas_x(self, x):
return (MalmoSim.CANVAS_BORDER/2) + (0.5 + x/float(MalmoSim.ARENA_WIDTH)) * (MalmoSim.CANVAS_WIDTH-MalmoSim.CANVAS_BORDER)
def canvas_y(self, y):
return (MalmoSim.CANVAS_BORDER/2) + (0.5 + y/float(MalmoSim.ARENA_BREADTH)) * (MalmoSim.CANVAS_HEIGHT-MalmoSim.CANVAS_BORDER)
def draw_mobs(self, entities, flash):
self.canvas.delete("all")
if flash:
self.canvas.create_rectangle(0,0,MalmoSim.CANVAS_WIDTH,MalmoSim.CANVAS_HEIGHT,fill="#ff0000") # Pain.
self.canvas.create_rectangle(self.canvas_x(-MalmoSim.ARENA_WIDTH/2), self.canvas_y(-MalmoSim.ARENA_BREADTH/2), self.canvas_x(MalmoSim.ARENA_WIDTH/2), self.canvas_y(MalmoSim.ARENA_BREADTH/2), fill="#888888")
for ent in entities:
if ent.name == MalmoSim.MOB_TYPE:
self.canvas.create_oval(self.canvas_x(ent.x)-2, self.canvas_y(ent.z)-2, self.canvas_x(ent.x)+2, self.canvas_y(ent.z)+2, fill="#ff2244")
elif ent.name == MalmoSim.GOAL_TYPE:
self.canvas.create_oval(self.canvas_x(ent.x)-3, self.canvas_y(ent.z)-3, self.canvas_x(ent.x)+3, self.canvas_y(ent.z)+3, fill="#4422ff")
else:
self.canvas.create_oval(self.canvas_x(ent.x)-4, self.canvas_y(ent.z)-4, self.canvas_x(ent.x)+4, self.canvas_y(ent.z)+4, fill="#22ff44")
self.root.update()
def create_actions(self):
'''Returns dictionary of actions that make up agent action space (turning)
'''
actions_dict = {}
for i in range(2,722):
#e.g., an i of 0 would give "turn -1"
actions_dict[i] = "turn " + str(((i-2)-360)/360)
actions_dict[0] = "move 1"
actions_dict[1] = "chat aaaaaaaaargh!"
return (actions_dict)
def run_sim(self, exp_role, num_episodes, port1, serv1, serv2, exp_id, epi, rsync):
'''Code to actually run simulation
'''
env = malmoenv.make()
env.init(self.get_mission_xml(MalmoSim.MOB_TYPE + " Apocalypse"),
port1, server=serv1,
server2=serv2, port2=(port1 + exp_role),
role=exp_role,
exp_uid=exp_id,
episode=epi,
resync=rsync,
action_space = malmoenv.ActionSpace(self.create_actions()))
max_num_steps = 1000
for r in range(num_episodes):
print("Reset [" + str(exp_role) + "] " + str(r) )
env.reset()
num_steps = 0
sim_done = False
total_reward = 0
total_commands = 0
flash = False
(obs, reward, sim_done, info) = env.step(0)
while not sim_done:
num_steps += 1
if (not (info is None or len(info) == 0)):
info_json = json.loads(info)
agent_life = info_json["Life"]
agent_yaw = info_json["Yaw"]
if "entities" in info_json:
entities = [EntityInfo(**k) for k in info_json["entities"]]
self.draw_mobs(entities, flash)
best_yaw_bin = self.agent_decision_net.classify_input(self.get_scores(entities, current_yaw, current_life))
best_yaw = sum((round(best_yaw_bin[x]) * (2**x)) for x in range(len(best_yaw_bin)))
num_bin_dig = int(math.ceil(math.log(self.agent_search_resolution,2)))
desired_output_bin = [int(x) for x in ('{0:0'+str(num_bin_dig)+'b}').format(desired_output)]
self.training_out.append(desired_output_bin)
self.training_obs.append(inputs)
difference = best_yaw - agent_yaw
#Sometimes we seem to get a difference above 360, still haven't figure out that one
while difference < -180:
difference += 360;
while difference > 180:
difference -= 360;
#Our action id is dependent upon our yaw angle to turn (see create_actions for more info)
action_id = int(difference + 360) + 2
(obs, reward, sim_done, info) = env.step(action_id)
#difference /= 180.0;
total_commands += 1
if (not(reward is None)):
total_reward += reward
else:
(obs, reward, sim_done, info) = env.step(0)
time.sleep(0.05)
print("We stayed alive for " + str(num_steps) + " commands, and scored " + str(total_reward))
time.sleep(1) # Give the mod a little time to prepare for the next mission.
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='malmovnv test')
parser.add_argument('--port', type=int, default=9000, help='the mission server port')
parser.add_argument('--server', type=str, default='127.0.0.1', help='the mission server DNS or IP address')
parser.add_argument('--server2', type=str, default=None, help="(Multi-agent) role N's server DNS or IP")
parser.add_argument('--port2', type=int, default=9000, help="(Multi-agent) role N's mission port")
parser.add_argument('--episodes', type=int, default=10, help='the number of resets to perform - default is 1')
parser.add_argument('--episode', type=int, default=0, help='the start episode - default is 0')
parser.add_argument('--resync', type=int, default=0, help='exit and re-sync on every N - default 0 meaning never')
parser.add_argument('--experimentUniqueId', type=str, default='test1', help="the experiment's unique id.")
args = parser.parse_args()
if args.server2 is None:
args.server2 = args.server
new_sim = MalmoSim()
new_sim.run_sim(0, args.episodes, args.port, args.server, args.server2,
args.experimentUniqueId, args.episode, args.resync)
Let's kill the lights and walk through the code

Top class constants
Here we specify a few parameters for our Minecraft environment, including which type of goal entity & Mob entity we'll use.
As mentioned previously, we're using a Silverfish here, you can checkout this link if you're interested in seeing other mobs that may be possible (depending on the conditions in the environment).
The parameters below the MOB_TYPE specify information for the side display window that helps you track your agent and the mob chasing it.
# Task parameters:
NUM_GOALS = 20
GOAL_TYPE = "apple"
GOAL_REWARD = 100
ARENA_WIDTH = 60
ARENA_BREADTH = 60
MOB_TYPE = "Silverfish" # Change for fun, but note that spawning conditions have to be correct - eg spiders will require darker conditions.
# Display parameters:
CANVAS_BORDER = 20
CANVAS_WIDTH = 400
CANVAS_HEIGHT = CANVAS_BORDER + ((CANVAS_WIDTH - CANVAS_BORDER) * ARENA_BREADTH / ARENA_WIDTH)
CANVAS_SCALEX = (CANVAS_WIDTH-CANVAS_BORDER)/ARENA_WIDTH
CANVAS_SCALEY = (CANVAS_HEIGHT-CANVAS_BORDER)/ARENA_BREADTH
CANVAS_ORGX = -ARENA_WIDTH/CANVAS_SCALEX
CANVAS_ORGY = -ARENA_BREADTH/CANVAS_SCALEY
The Constructor
Here, we specify weights for how we might consider the entities around us (e.g., a mob entity). This will affect the get_scores method discussed below. get_scores will act as a possible of ground truth (i.e., potentially what you want your Decision Engine to output).
The _weight attributes will be important if you decide to use the given get_scores method as they are used by that method.
Notice that we also define an agent_decision_net attribute. You may or may not define it in a similar way, but you want to make it so you can easily swap out the Decision Engine. Defining an attribute could be one way, though the better design may be to instead define a whole agent attribute that is an instance of your whole AI agent architecture. It will be up to you to decide how you are going to handle the swappable agent.
Another thing to notice is that we have attributes for training_obs and training_out. When you set out to initially train the NN underlying your Decision Engine, remember that you might consider to record a log of observations and outputs. You could potentially then use this log to train your NN without having to run Minecraft more times.
def __init__(self, step_size=1, search_resolution=20, goal_weight=100, \
edge_weight=-100, mob_weight=-10, turn_weight=0):
# Agent parameters:
self.agent_step_size = step_size
self.agent_search_resolution = search_resolution # Smaller values make computation faster, which seems to offset any benefit from the higher resolution.
self.agent_goal_weight = goal_weight
self.agent_edge_weight = edge_weight
self.agent_mob_weight = mob_weight
self.agent_turn_weight = turn_weight # Negative values to penalise turning, positive to encourage.
#output is the binary representation of our output index ([o,search_resolution))
self.agent_decision_net = NeuralMMAgent(search_resolution, \
search_resolution, 2, math.ceil(math.log(search_resolution,2)), \
random_seed=10, max_epoch=50000, learning_rate=0.25, momentum=0.95)
self.training_obs = []
self.training_out = []
self.recordings_directory="FleeRecordings"
try:
os.makedirs(self.recordings_directory)
except OSError as exception:
if exception.errno != errno.EEXIST: # ignore error if already existed
raise
self.root = tk.Tk()
self.root.wm_title("Collect the " + MalmoSim.GOAL_TYPE + "s, dodge the " + MalmoSim.MOB_TYPE + "s!")
self.canvas = tk.Canvas(self.root, width=MalmoSim.CANVAS_WIDTH, height=MalmoSim.CANVAS_HEIGHT, borderwidth=0, highlightthickness=0, bg="black")
self.canvas.pack()
self.root.update()
XML Mission code
Next, we have code that constructs our environment/mission. I won't go into detail here.
Some of it is straightforward, but if you want to understand it in detail take a look at the documentation
def get_item_xml(self):
''' Build an XML string that contains some randomly positioned goal items'''
xml=""
for item in range(MalmoSim.NUM_GOALS):
x = str(random.randint(-MalmoSim.ARENA_WIDTH/2,MalmoSim.ARENA_WIDTH/2))
z = str(random.randint(-MalmoSim.ARENA_BREADTH/2,MalmoSim.ARENA_BREADTH/2))
xml += '''<DrawItem x="''' + x + '''" y="210" z="''' + z + '''" type="''' + MalmoSim.GOAL_TYPE + '''"/>'''
return xml
def get_corner(self, index,top,left,expand=0,y=206):
''' Return part of the XML string that defines the requested corner'''
x = str(-int(expand+MalmoSim.ARENA_WIDTH/2)) if left else str(int(expand+MalmoSim.ARENA_WIDTH/2))
z = str(-int(expand+MalmoSim.ARENA_BREADTH/2)) if top else str(int(expand+MalmoSim.ARENA_BREADTH/2))
return 'x'+index+'="'+x+'" y'+index+'="' +str(y)+'" z'+index+'="'+z+'"'
def get_mission_xml(self, summary):
''' Build an XML mission string.'''
spawn_end_tag = ' type="mob_spawner" variant="' + MalmoSim.MOB_TYPE + '"/>'
return '''<?xml version="1.0" encoding="UTF-8" ?>
<Mission xmlns="http://ProjectMalmo.microsoft.com" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<About>
<Summary>''' + summary + '''</Summary>
</About>
<ModSettings>
<MsPerTick>20</MsPerTick>
</ModSettings>
<ServerSection>
<ServerInitialConditions>
<Time>
<StartTime>13000</StartTime>
<AllowPassageOfTime>false</AllowPassageOfTime>
</Time>
<AllowSpawning>true</AllowSpawning>
<AllowedMobs>''' + MalmoSim.MOB_TYPE + '''</AllowedMobs>
</ServerInitialConditions>
<ServerHandlers>
<FlatWorldGenerator generatorString="3;7,220*1,5*3,2;3;,biome_1" />
<DrawingDecorator>
<DrawCuboid ''' + self.get_corner("1",True,True,expand=1) + " " + self.get_corner("2",False,False,y=226,expand=1) + ''' type="grass"/>
<DrawCuboid ''' + self.get_corner("1",True,True,y=207) + " " + self.get_corner("2",False,False,y=226) + ''' type="air"/>
<DrawLine ''' + self.get_corner("1",True,True) + " " + self.get_corner("2",True,False) + spawn_end_tag + '''
<DrawLine ''' + self.get_corner("1",True,True) + " " + self.get_corner("2",False,True) + spawn_end_tag + '''
<DrawLine ''' + self.get_corner("1",False,False) + " " + self.get_corner("2",True,False) + spawn_end_tag + '''
<DrawLine ''' + self.get_corner("1",False,False) + " " + self.get_corner("2",False,True) + spawn_end_tag + '''
<DrawCuboid x1="-1" y1="206" z1="-1" x2="1" y2="206" z2="1" ''' + spawn_end_tag + '''
''' + self.get_item_xml() + '''
</DrawingDecorator>
<ServerQuitWhenAnyAgentFinishes />
</ServerHandlers>
</ServerSection>
<AgentSection mode="Survival">
<Name>The Hunted</Name>
<AgentStart>
<Placement x="0.5" y="207.0" z="0.5"/>
<Inventory>
</Inventory>
</AgentStart>
<AgentHandlers>
<VideoProducer want_depth="false">
<Width>640</Width>
<Height>480</Height>
</VideoProducer>
<ChatCommands/>
<ContinuousMovementCommands turnSpeedDegs="360"/>
<AbsoluteMovementCommands/>
<ObservationFromNearbyEntities>
<Range name="entities" xrange="'''+str(MalmoSim.ARENA_WIDTH)+'''" yrange="2" zrange="'''+str(MalmoSim.ARENA_BREADTH)+'''" />
</ObservationFromNearbyEntities>
<ObservationFromFullStats/>
<RewardForCollectingItem>
<Item type="'''+MalmoSim.GOAL_TYPE+'''" reward="'''+str(MalmoSim.GOAL_REWARD)+'''"/>
</RewardForCollectingItem>
</AgentHandlers>
</AgentSection>
</Mission>'''
Finding the AI agent, the entities around, and scoring the agent's next move
The first method up is the find_us method. This simply finds the AI agent amongst the list of entities. With what is returned, we'll know the current state of the AI agent.
get_scores is liikely to be a very important method for your design & agent. This method
Though, you don't have to use it, you might want to at least use the get_scores method initially to get all other aspects up and running before you get fancy. agent_search_resolution is used to determine how many possibilities your agent will go through, how much detail your agent will deal with. The larger the search resolution, the higher the number of angles the agent considers turning (i.e., what direction it will head in next).
For each possible turning angle, the agent sums a calculation of cost for potentially choosing that angle/yaw for every entity in our list of entities. This is where the _weight attributes (e.g., agent_turn_weight) come into play - they are used to weight the value of minimizing the distance between the agent and the entity (or for the agent_turn_weight the cost of turning a certain distance).
The last few lines can help keep the agent out of a corner (but certainly won't guarantee it!)
The get_best_angle method simply uses that get_scores method to return the angle at which the agent would have the best score.
You might notice that get_best_angle is never used in the actual code. Maybe that's because some neural-network is trying to approximate it in the simulation loop 👀.
def find_us(self, entities):
''' Find (& return) the agent amongst the list of entities
'''
for ent in entities:
if ent.name == MalmoSim.MOB_TYPE:
continue
elif ent.name == MalmoSim.GOAL_TYPE:
continue
else:
return ent
def get_scores(self, entities, current_yaw, current_health):
''' Returns a list of scores that we can use to determine the best turning angle
'''
us = self.find_us(entities)
scores=[]
# Normalise current yaw:
while current_yaw < 0:
current_yaw += 360
while current_yaw > 360:
current_yaw -= 360
# Look for best option
for i in range(self.agent_search_resolution):
# Calculate cost of turning:
ang = 2 * math.pi * (i / float(self.agent_search_resolution))
yaw = i * 360.0 / float(self.agent_search_resolution)
yawdist = min(abs(yaw-current_yaw), 360-abs(yaw-current_yaw))
turncost = self.agent_turn_weight * yawdist
score = turncost
# Calculate entity proximity cost for new (x,z):
x = us.x + self.agent_step_size - math.sin(ang)
z = us.z + self.agent_step_size * math.cos(ang)
for ent in entities:
dist = (ent.x - x)*(ent.x - x) + (ent.z - z)*(ent.z - z)
if (dist == 0):
continue
weight = 0.0
if ent.name == MalmoSim.MOB_TYPE:
weight = self.agent_mob_weight
dist -= 1 # assume mobs are moving towards us
if dist <= 0:
dist = 0.1
elif ent.name == MalmoSim.GOAL_TYPE:
weight = self.agent_goal_weight * current_health / 20.0
score += weight / float(dist)
# Calculate cost of proximity to edges:
distRight = (2+MalmoSim.ARENA_WIDTH/2) - x
distLeft = (-2-MalmoSim.ARENA_WIDTH/2) - x
distTop = (2+MalmoSim.ARENA_BREADTH/2) - z
distBottom = (-2-MalmoSim.ARENA_BREADTH/2) - z
score += self.agent_edge_weight / float(distRight * distRight * distRight * distRight)
score += self.agent_edge_weight / float(distLeft * distLeft * distLeft * distLeft)
score += self.agent_edge_weight / float(distTop * distTop * distTop * distTop)
score += self.agent_edge_weight / float(distBottom * distBottom * distBottom * distBottom)
scores.append(score)
return (scores)
def get_best_angle(self, entities, current_yaw, current_health):
'''Scan through 360 degrees, looking for the best direction in which to take the next step.'''
scores = self.get_scores(entities, current_yaw, current_health)
# Find best score:
i = scores.index(max(scores))
# Return as an angle in degrees:
return (i, scores, i * 360.0 / float(self.agent_search_resolution))
Helper window drawing code
This code is used to draw the mobs on the helper tkinter window. If you want to do something creative, you might need to understand the code a bit, but you probably won't need much more than to include the code.
def canvas_x(self, x):
return (MalmoSim.CANVAS_BORDER/2) + (0.5 + x/float(MalmoSim.ARENA_WIDTH)) * (MalmoSim.CANVAS_WIDTH-MalmoSim.CANVAS_BORDER)
def canvas_y(self, y):
return (MalmoSim.CANVAS_BORDER/2) + (0.5 + y/float(MalmoSim.ARENA_BREADTH)) * (MalmoSim.CANVAS_HEIGHT-MalmoSim.CANVAS_BORDER)
def draw_mobs(self, entities, flash):
self.canvas.delete("all")
if flash:
self.canvas.create_rectangle(0,0,MalmoSim.CANVAS_WIDTH,MalmoSim.CANVAS_HEIGHT,fill="#ff0000") # Pain.
self.canvas.create_rectangle(self.canvas_x(-MalmoSim.ARENA_WIDTH/2), self.canvas_y(-MalmoSim.ARENA_BREADTH/2), self.canvas_x(MalmoSim.ARENA_WIDTH/2), self.canvas_y(MalmoSim.ARENA_BREADTH/2), fill="#888888")
for ent in entities:
if ent.name == MalmoSim.MOB_TYPE:
self.canvas.create_oval(self.canvas_x(ent.x)-2, self.canvas_y(ent.z)-2, self.canvas_x(ent.x)+2, self.canvas_y(ent.z)+2, fill="#ff2244")
elif ent.name == MalmoSim.GOAL_TYPE:
self.canvas.create_oval(self.canvas_x(ent.x)-3, self.canvas_y(ent.z)-3, self.canvas_x(ent.x)+3, self.canvas_y(ent.z)+3, fill="#4422ff")
else:
self.canvas.create_oval(self.canvas_x(ent.x)-4, self.canvas_y(ent.z)-4, self.canvas_x(ent.x)+4, self.canvas_y(ent.z)+4, fill="#22ff44")
self.root.update()
Malmoenv (gym) actions
So that we can tell Malmo how to move using the gym-like api (learn more about gym by clicking here), we specify the actions that will make up our action_space using the create_actions method
def create_actions(self):
'''Returns dictionary of actions that make up agent action space (turning)
'''
actions_dict = {}
for i in range(2,722):
#e.g., an i of 0 would give "turn -1"
actions_dict[i] = "turn " + str(((i-2)-360)/360)
actions_dict[0] = "move 1"
actions_dict[1] = "chat aaaaaaaaargh!"
return (actions_dict)
Running the simulation
Last (but certainly not least), we need to run the simulation
Initialize the environment
First, we make and initialize our environment (you shouldn't have to worry too much about this bit, but note the use of the create_actions method described above)
def run_sim(self, exp_role, num_episodes, port1, serv1, serv2, exp_id, epi, rsync):
'''Code to actually run simulation
'''
env = malmoenv.make()
env.init(self.get_mission_xml(MalmoSim.MOB_TYPE + " Apocalypse"),
port1, server=serv1,
server2=serv2, port2=(port1 + exp_role),
role=exp_role,
exp_uid=exp_id,
episode=epi,
resync=rsync,
action_space = malmoenv.ActionSpace(self.create_actions()))
max_num_steps = 1000
The episode loop
Now we run a loop so that we can repeat our simulation as a number of episodes. Every simulation (basically until the agent dies) is one episode here.
At the beginning of every episode, we tell the agent to start moving forward using env.step(0). With create_actions, we created a list of potential actions, each with a uid. The action with a uid of 0 is move 1.
for r in range(num_episodes):
print("Reset [" + str(exp_role) + "] " + str(r) )
env.reset()
num_steps = 0
sim_done = False
total_reward = 0
total_commands = 0
flash = False
(obs, reward, sim_done, info) = env.step(0)
The simulation loop
Here is where a lot of the action happens. sim_done will be set to True when the mission completes (your AI agent dies).
When we get information from the environment (the if statement), we convert that json to dictionaries to make things a bit easier and get the agent's life and position. We also get all the entity information with entities = [EntityInfo(**k) for k in info_json["entities"]].
Here, I use an example decision engine (network) to make a decision on which angle to take based on the given scores for each potential angle.
There are potentially many ways to make a "decision".
This agent outputs an angle in binary. Why?

The agent then converts that output into an angle to turn (difference). This angle is converted to an action_id (that action uid we were just discussing) so that we can call the correct action (turn) can be carried out. We know we can only turn so many degrees (assuming integers from -360 to 360, we could have done 0 to 360...I don't remember why I didn't do 0 to 360 /shrug), so we were able to create those actions a priori.
while not sim_done:
num_steps += 1
if (not (info is None or len(info) == 0)):
info_json = json.loads(info)
agent_life = info_json["Life"]
agent_yaw = info_json["Yaw"]
if "entities" in info_json:
entities = [EntityInfo(**k) for k in info_json["entities"]]
self.draw_mobs(entities, flash)
best_yaw_bin = self.agent_decision_net.classify_input(self.get_scores(entities, current_yaw, current_life))
best_yaw = sum((round(best_yaw_bin[x]) * (2**x)) for x in range(len(best_yaw_bin)))
num_bin_dig = int(math.ceil(math.log(self.agent_search_resolution,2)))
desired_output_bin = [int(x) for x in ('{0:0'+str(num_bin_dig)+'b}').format(desired_output)]
self.training_out.append(desired_output_bin)
self.training_obs.append(inputs)
difference = best_yaw - agent_yaw
#Sometimes we seem to get a difference above 360, still haven't figure out that one
while difference < -180:
difference += 360;
while difference > 180:
difference -= 360;
#Our action id is dependent upon our yaw angle to turn (see create_actions for more info)
action_id = int(difference + 360) + 2
(obs, reward, sim_done, info) = env.step(action_id)
#difference /= 180.0;
total_commands += 1
if (not(reward is None)):
total_reward += reward
else:
(obs, reward, sim_done, info) = env.step(0)
time.sleep(0.05)
Finishing up
To finish up, we print out the stats for the number of steps we stayed alive and the total reward we were able to get.
The code below is just the code that allows us to run our file from the command line (e.g., $python MalmoSim.py)
print("We stayed alive for " + str(num_steps) + " commands, and scored " + str(total_reward))
time.sleep(1) # Give the mod a little time to prepare for the next mission.
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='malmovnv test')
parser.add_argument('--port', type=int, default=9000, help='the mission server port')
parser.add_argument('--server', type=str, default='127.0.0.1', help='the mission server DNS or IP address')
parser.add_argument('--server2', type=str, default=None, help="(Multi-agent) role N's server DNS or IP")
parser.add_argument('--port2', type=int, default=9000, help="(Multi-agent) role N's mission port")
parser.add_argument('--episodes', type=int, default=10, help='the number of resets to perform - default is 1')
parser.add_argument('--episode', type=int, default=0, help='the start episode - default is 0')
parser.add_argument('--resync', type=int, default=0, help='exit and re-sync on every N - default 0 meaning never')
parser.add_argument('--experimentUniqueId', type=str, default='test1', help="the experiment's unique id.")
args = parser.parse_args()
if args.server2 is None:
args.server2 = args.server
new_sim = MalmoSim()
new_sim.run_sim(0, args.episodes, args.port, args.server, args.server2,
args.experimentUniqueId, args.episode, args.resync)
Note, I include this below in case you wanted to see what shell code for a custom Neural Net might look like, you are not required to write your own Neural Net class for this assignment
Neural Net Shell Code
# Some potentially useful modules
# Whether or not you use these (or others) depends on your implementation!
import random
import numpy
import math
import matplotlib.pyplot as plt
class NeuralMMAgent(object):
'''
Class to for Neural Net Agents
'''
def __init__(self, num_in_nodes, num_hid_nodes, num_hid_layers, num_out_nodes, \
learning_rate = 0.2, max_epoch=10000, max_sse=.01, momentum=0.2, \
creation_function=None, activation_function=None, random_seed=1):
'''
Arguments:
num_in_nodes -- total # of input nodes for Neural Net
num_hid_nodes -- total # of hidden nodes for each hidden layer
in the Neural Net
num_hid_layers -- total # of hidden layers for Neural Net
num_out_nodes -- total # of output nodes for Neural Net
learning_rate -- learning rate to be used when propagating error
creation_function -- function that will be used to create the
neural network given the input
activation_function -- list of two functions:
1st function will be used by network to determine activation given a weighted summed input
2nd function will be the derivative of the 1st function
random_seed -- used to seed object random attribute.
This ensures that we can reproduce results if wanted
'''
assert num_in_nodes > 0 and num_hid_layers > 0 and num_hid_nodes and\
num_out_nodes > 0, "Illegal number of input, hidden, or output layers!"
def train_net(self, input_list, output_list, max_num_epoch=100000, \
max_sse=0.1):
''' Trains neural net using incremental learning
(update once per input-output pair)
Arguments:
input_list -- 2D list of inputs
output_list -- 2D list of outputs matching inputs
'''
#Some code...#
all_err.append(total_err)
if (total_err < max_sse):
break
#Show us how our error has changed
plt.plot(all_err)
plt.show()
def _calculate_deltas(self):
'''Used to calculate all weight deltas for our neural net
Arguments:
out_error -- output error (typically SSE), obtained using target
output and actual output
'''
#Calculate error gradient for each output node & propgate error
# (calculate weight deltas going backward from output_nodes)
def _adjust_weights_thetas(self):
'''Used to apply deltas
'''
@staticmethod
def create_neural_structure(num_in, num_hid, num_hid_layers, num_out, rand_obj):
''' Creates the structures needed for a simple backprop neural net
This method creates random weights [-0.5, 0.5]
Arguments:
num_in -- total # of input nodes for Neural Net
num_hid -- total # of hidden nodes for each hidden layer
in the Neural Net
num_hid_layers -- total # of hidden layers for Neural Net
num_out -- total # of output nodes for Neural Net
rand_obj -- the random object that will be used to selecting
random weights
Outputs:
Tuple w/ the following items
1st - 2D list of initial weights
2nd - 2D list for weight deltas
3rd - 2D list for activations
4th - 2D list for errors
5th - 2D list of thetas for threshold
6th - 2D list for thetas deltas
'''
#-----Begin ACCESSORS-----#
#-----End ACCESSORS-----#
@staticmethod
def sigmoid_af(summed_input):
#Sigmoid function
@staticmethod
def sigmoid_af_deriv(sig_output):
#the derivative of the sigmoid function
test_agent = NeuralMMAgent(2, 2, 1, 1,random_seed=5, max_epoch=1000000, \
learning_rate=0.2, momentum=0)
test_in = [[1,0],[0,0],[1,1],[0,1]]
test_out = [[1],[0],[0],[1]]
test_agent.set_weights([[-.37,.26,.1,-.24],[-.01,-.05]])
test_agent.set_thetas([[0,0],[0,0],[0]])
test_agent.train_net(test_in, test_out, max_sse = test_agent.max_sse, \
max_num_epoch = test_agent.max_epoch)
Let's go through some of this code
First things first, our constructor
This constructor expects the user to specify the number of inputs, hidden nodes, hidden layers, and output nodes
To make things a bit more simple, we are assuming that all of our hidden layers will have the same number of nodes.
Most of the other arguments are, essentially, optional. However, the creation_function and the activation_function are important and you will have to create/specify those. For you activation function, you must at least implement the sigmoid function.
def __init__(self, num_in_nodes, num_hid_nodes, num_hid_layers, num_out_nodes, \
learning_rate = 0.2, max_epoch=10000, max_sse=.01, momentum=0, \
creation_function=None, activation_function=None, random_seed=1):
'''
Arguments:
num_in_nodes -- total # of input nodes for Neural Net
num_hid_nodes -- total # of hidden nodes for each hidden layer
in the Neural Net
num_hid_layers -- total # of hidden layers for Neural Net
num_out_nodes -- total # of output nodes for Neural Net
learning_rate -- learning rate to be used when propagating error
creation_function -- function that will be used to create the
neural network given the input
activation_function -- list of two functions:
1st function will be used by network to determine activation given a weighted summed input
2nd function will be the derivative of the 1st function
random_seed -- used to seed object random attribute.
This ensures that we can reproduce results if wanted
'''
assert num_in_nodes > 0 and num_hid_layers > 0 and num_hid_nodes and\
num_out_nodes > 0, "Illegal number of input, hidden, or output layers!"
train_net is where the action is
This method is used to do the heavy lifting, that is, train your neural net, and report our error.
The network configuration should be saved within the network itself at the end of the training
def train_net(self, input_list, output_list, max_num_epoch=100000, \
max_sse=0.1):
''' Trains neural net using incremental learning
(update once per input-output pair)
Arguments:
input_list -- 2D list/array of inputs
output_list -- 2D list/array of outputs matching inputs
'''
#Some code...#
all_err.append(total_err)
if (total_err < max_sse):
break
#Show us how our error has changed
plt.plot(all_err)
plt.show()
learning in the network
Your network will be learning using the functions above.
As I noted below you'll want to calculate all of your deltas before updating things. Thus, we have two functions to handle the calculations and application of the results of these calculations
def _calculate_deltas(self):
'''Used to calculate all weight deltas for our neural net
'''
#Calculate error gradient for each output node & propgate error
# (calculate weight deltas going backward from output_nodes)
def _adjust_weights_thetas(self):
'''Used to apply deltas
'''
This will initialize our neural network
I suggest a particular way to output the resulting NN structure (that is, internally it is a Tuple of lists)
You could also use, say, numpy to create a neural network based in matrices (this would be faster tha lists, but may be more difficult depending on your mathematical background)
@staticmethod
def create_neural_structure(num_in, num_hid, num_hid_layers, num_out, rand_obj):
''' Creates the structures needed for a simple backprop neural net
This method creates random weights [-0.5, 0.5]
Arguments:
num_in -- total # of input layers for Neural Net
num_hid -- total # of hidden nodes for each hidden layer
in the Neural Net
num_hid_layers -- total # of hidden layers for Neural Net
num_out -- total # of output layers for Neural Net
rand_obj -- the random object that will be used to selecting
random weights
Outputs:
Tuple w/ the following items
1st - 2D list/array of initial weights
2nd - 2D list/array for weight deltas
3rd - 2D list/array for activations
4th - 2D list/array for errors
5th - 2D list/array of thetas for threshold
6th - 2D list/array for thetas deltas
'''
#-----Begin ACCESSORS-----#
#-----End ACCESSORS-----#
now lets & initialize & run our network
Finally, note that while I've gone through the normal constructor process to initialize my neural net in the code above, I also artificially set the weights and the thetas (-bias) to what we used as our example in class. This should help you ensure that your network at least runs correctly on one pass.
It will be up to you to ensure that your neural network works as it should!
Again, here we're assuming python lists to hold values rather than using numpy matrices, and that is reflected in the way we set initial values.
test_agent = NeuralMMAgent(2, 2, 1, 1, random_seed=5, max_epoch=1000000, \
learning_rate=0.2, momentum=0)
test_in = [[1,0],[0,0],[1,1],[0,1]]
test_out = [[1],[0],[0],[1]]
test_agent.set_weights([[-.37,.26,.1,-.24],[-.01,-.05]])
test_agent.set_thetas([[0,0],[0,0],[0]])
test_agent.train_net(test_in, test_out, max_sse = test_agent.max_sse, \
max_num_epoch = test_agent.max_epoch)
Notes
- You'll want to include a threshold and/or bias here. As I've gone over in class, you should also calculate a delta for the threshold/bias and change thetas during the same steps where they update the weights
- DON'T FORGET TO CALCULATE ALL OF YOUR WEIGHT DELTAS BEFORE UPDATING ANY OF THE WEIGHTS (you can get by without calculating all the weight deltas, but you should be sure if you're doing things correctly if you end up not updating all weight deltas 1st)
- There are many ways you can optimize your code. When in doubt I'd advise to take the easier, less optimal route to improve your progress (you can always go back for optimizations!)
- At a minimum, your neural net will need 2 input, 2 hidden (1 layer), 2 output to solve XOR
- Using Numpy is nice, but unless you are really confident w/ that, I think python lists are going to be faster to code up for this (the
zipfunction is helpful if you use built-in python sequences) - You can use matplotlib.pyplot to easily plot the SSE reducing over epochs
- (it's a nice way to see what's happening to your SSE if you suspect your error isn't reducing correctly)